
如何使用 Lanraragi 和 Calibre 来构建本子库
开始教程之前
1. 什么是 Calibre 和 Lanraragi ?
Lanraragi
项目地址:https://github.com/Difegue/LANraragi
支持平台:linux、windows
是一个多平台开源漫画服务器,可以将本地或是服务器/nas上的漫画文件展示出来。其主要特点有下面几点。
优点
- 支持 zip/rar/targz/lzma/7z/xz/cbz/cbr/pdf ,以及对 epub 的基本支持。基本上你所拥有的漫画都可以被读取
- 直接从 WEB 浏览器读取图片,服务器使用临时文件夹从压缩文件中读取原档,如果带宽较低的话还可以通过服务端实时压缩图片来降低带宽压力
- 内置 OPDS 和 API ,可以通过第三方客户端来读取内容
- 实时监测文件库的变动,可自动添加新内容到数据库中,并自动调用插件进行刮削元数据。
- 可通过输入下载链接直接下载文件到服务器上,并且支持上述的插件刮削。
- 支持数据库备份为 JSON ,方便迁移
- 不破坏本地路径,只需要将自己成堆的漫画库设置为档案库即可,不需要单独复制一份来额外占用空间
缺点
- 文件管理操作不便,网页端没法直观的对文件库进行删改操作
- 刮削进程不可控,如果因为文件命名导致刮削失败也很难进行批量处理
- 本身没有对系列漫画归档的设计,对于普通漫画来说不太友好
Calibre

Calibre 是一个开源的电子书软件,也可以说是世界上目前功能最完善的电子书管理软件,支持绝大多数的电子书格式。漫画的几种常见格式自然也是支持的,除了管理漫画外,用于管理轻小说等电子书也是不错的选择。
2. 我为什么需要这篇教程?
因为你和我一样都具有仓鼠症,但对于常年累月积攒下来的“优质”漫画的整理又无从下手,整理起来又有以下几个问题
①不方便进行分类,以作者分类不方便xp检索,以xp分类也不方便找同作者的其他本子
②希望能在手机或是其他地方实时检索本子或是观看
③以前积累的本子太多,整理起来太累,就全部堆到一个文件夹里。
3. 看完这篇教程你能收获什么?
一个较为规整的本地漫画库,并且可以方便的通过移动设备或是外网串流实时观看。除此之外,以后的新漫画都可以自动化的获取标签并入库。
Calibre的安装与使用
1. 安装软件
首先从 Calibre 下载页面选择对应的版本下载安装,安装的时候顺着向导一路向下走即可,中间创建书库时可以直接选择本地或者是 NAS 上的空白文件夹。
2. 调整配置
Calibre 最让人诟病的一点就是很多设置描述显得模棱两可,或者是想要修改的地方找不到,所以我直接把我所使用的配置文件分享出来,按照压缩包内的说明文档,直接覆盖软件的配置文件夹即可。
懒人包:https://pan.baidu.com/s/1OMxYgnfoWuzE3gZeksnTQA?pwd=fdau
提取码:fdau
密码:kame
其中汉化修复的效果是使 Calibre 所导入的文件不要变成拼音,这点本来是为了方便软件建立数据库的,但是谁也不想自己收集的文件全部变成拼音命名吧。
3. 基本使用
网上如果检索 Calibre 的教程,大多也只是较为浅显的使用一下,不过关于我们需要整理的漫画,恰好有两篇写的非常不错的。
看完了以后基本上对于这个软件算是入门了,不过教程中的录入元数据的操作需要稍微改进一下(如果直接使用懒人包可以跳过下面几条,因为可以直接用了)。
4. 修改加入文件时的正则匹配表达式
漫画一般包括有作者、题名、作品来源和汉化组名字,我们需要提取其中有价值的部分,并且重新封装成新的文件名。
通过上面文章中的正则可以匹配出大部分漫画的作者和提名,我在此基础上进一步增加了提取原作名字的正则,最后表达式如下:
(?P<comments>.*?\[(?P<author>(?:(?!汉化|漢化)[^\[\]])*)\](?:\s*(?:\[[^\(\)]+\]|\([^\[\]\(\)]+\))\s*)*(?P<title>[^\[\]\(\)]+).*?(\((?P<publisher>[^\(\)]*)\))?.*)
保存设置后,只需要往 Calibre 书库中拖动漫画,便会自动识别以上的信息。
5. 修改文件的保存命名
由于软件是新建的书库,需要将漫画文件导入其中,如果想要再留一份原档的话,那就是双倍占用空间。如果直接使用原版软件,会导致导入的文件名均被软件转换为拼音

下面给出解决方案
Calibre 中文文件名修正
项目地址:https://github.com/kurikomoe/calibre-utf8-path
下载后进行覆盖软件的文件,并通过批处理文件启动文件,此时软件会以调试模式启动,运行修改过后的代码,这样导入的文件就不会变为英文,并且不会影响软件的本身运行。
不过单纯就这样启动以后,还会发现虽然文件名变回中文了,但较长的文件名却被裁剪了,例如

所以我们还需要对源码进行修改,需要修改的文件是~Calibre\src\calibre\db\backend.py
def construct_path_name(self, book_id, title, author):
'''
Construct the directory name for this book based on its metadata.
'''
book_id = ' (%d)' % book_id
l = self.PATH_LIMIT
author = ascii_filename(author)[:l]
title = ascii_filename(title.lstrip()).rstrip()
if not title:
title = 'Unknown'[:l]
try:
while author[-1] in (' ', '.'):
author = author[:-1]
except IndexError:
author = ''
if not author:
author = ascii_filename(_('Unknown'))
if author.upper() in WINDOWS_RESERVED_NAMES:
author += 'w'
return f'{author}/[{author}]{title}{book_id}'
def construct_file_name(self, book_id, title, author, extlen):
'''
Construct the file name for this book based on its metadata.
'''
extlen = max(extlen, 0) # 14 accounts for ORIGINAL_EPUB
# The PATH_LIMIT on windows already takes into account the doubling
# (it is used to enforce the total path length limit, individual path
# components can be much longer than the total path length would allow on
# windows).
l = (self.PATH_LIMIT) if iswindows else (self.PATH_LIMIT)
if l < 5:
raise ValueError('Extension length too long: %d' % extlen)
author = ascii_filename(author)[:l]
title = ascii_filename(title.lstrip()).rstrip()
if not title:
title = 'Unknown'[:l]
name = '[' + author + ']' +title
while name.endswith('.'):
name = name[:l]
if not name:
name = ascii_filename(_('Unknown'))
return name
经过这样改动后,无论是多长的文件名都可以原样保存,由于我是按照本子的命名格式调整的,如果有自己的想法也可以自行改动上面的第20行和第37行代码,分别对应文件夹命名和文件命名的。
此外在e站去年的改动中,1280x重采样下载下来的图像格式为webp,并不能被calibre识别为漫画格式的压缩包,所以这里我们同样也需要修改一下源代码,需要修改的文件是~Calibre\src\calibre\ebooks\comic\metadata\archive.py
def is_comic(list_of_names):
extensions = {x.rpartition('.')[-1].lower() for x in list_of_names
if '.' in x and x.lower().rpartition('/')[-1] != 'thumbs.db'}
comic_extensions = {'jpg', 'jpeg', 'png', 'gif', 'webp', 'bmp'} #只需要在这里增加常见的图片格式即可
return len(extensions - comic_extensions) == 0
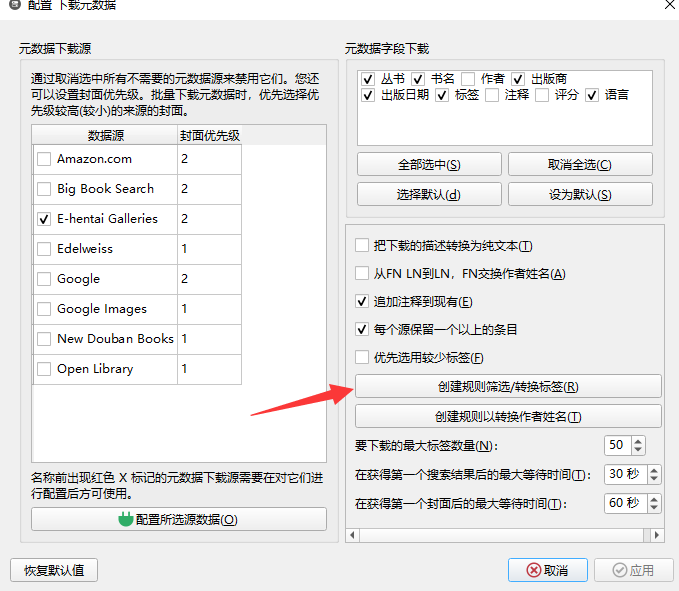
6. 添加元数据刮取插件
E站本子元数据下载插件
项目地址:https://github.com/nonpricklycactus/Ehentai_metadata
从 Github 上下载插件后可以在 Calibre 中的首选项-插件-从文件中加载插件,进行导入。
导入后需要配置自己的E站Cookies和翻译的数据库,前者需要自己的账号,推荐使用里站的账号,毕竟有些本子外站搜索不到。而后者则可以在上面插件的项目地址中下载EhTagTranslation.db文件,在插件配置中填好路径即可。
使用Tips:
①本子的名字对于刮削来说非常重要,有时候搜索不到可以删掉一部分名字或者删除作者名。
②如果上述操作还是找不到本子,可以自己上E站尝试搜索,如果也搜不到说明画廊可能被删除或屏蔽,还有一种概率比较小的是本子此时没有被打 tag ,这种情况下插件依旧会返回错误。
③如果找得到但是插件搜索不到,可以开启插件的 Accurate_Label 选项,手动填写本子的链接。
7. 修改标签映射器
直接刮取下来的 Tag 大多为女性:xx,看起来不太美观,并且可能有些 Tag 所表述的意思是重复的,可以进行合并,又或者其中的一部分 Tag 是没有意义的,需要删除。此时可以使用 Calibre 的标签映射器来自动转换这些 Tag。
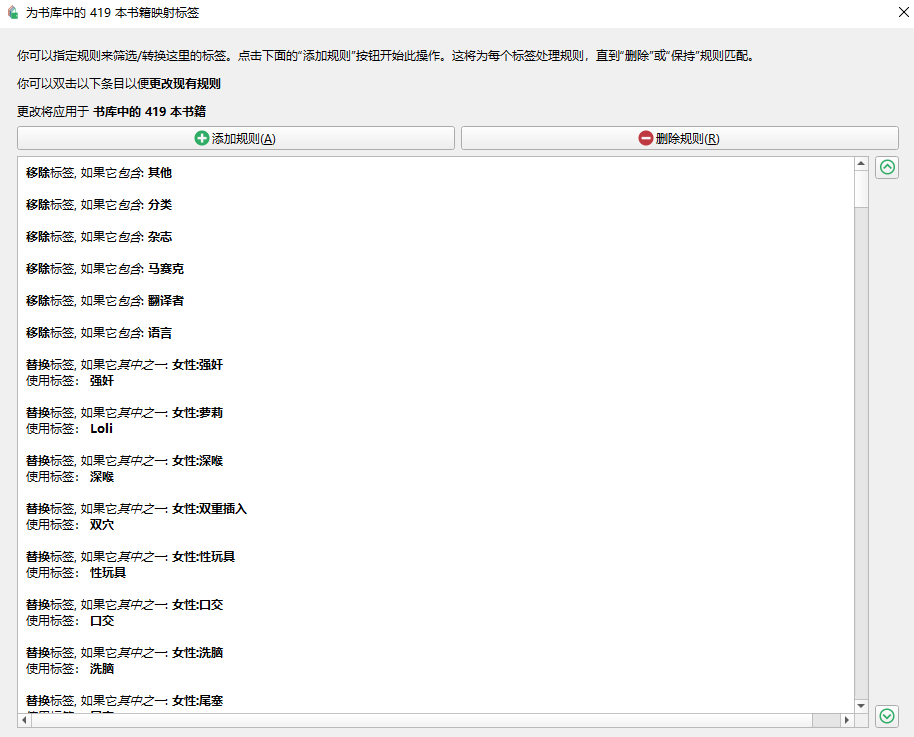
这个工具默认不显示出来,需要在首选项-工具栏与菜单-主工具栏左侧选择后,才能在上方的工具栏中看到它。
需要注意的是,当你进行改动后按下确定,会直接对当前显示的所有的文件的标签按规则进行整理,最好先做好测试以后再进行下一步操作。
当规则设置好后,可以按下面的保存,将当前的规则列表保存一份。之后在元数据获取配置里将规则进行同步,这样刮削后会直接按规则进行转换。
8. 重复文件检索
这里使用的是 Find Duplicates 插件,可以直接在 Calibre 的插件库中搜索到。这个软件可以通过比对作者名和文件名的相似程度来进行去重。
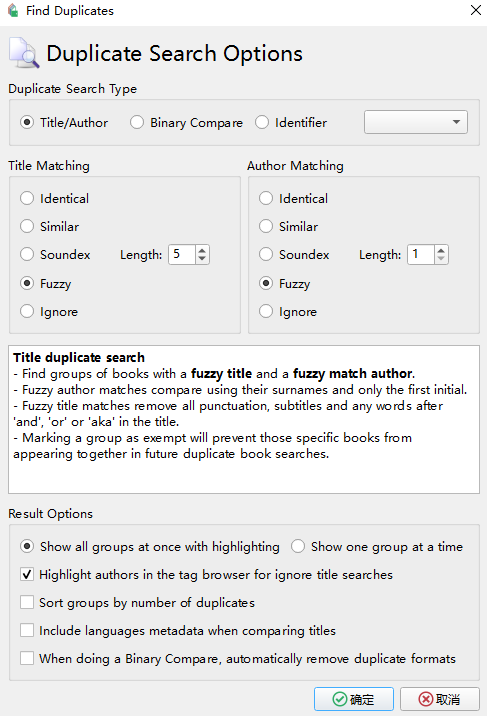
当你的本子库大到一定程度的情况下,这个插件是非常实用的,我目前1w5本的情况下,这个插件也仅需几秒便可检索完成。
Lanraragi的安装与使用
1. 安装软件
首先从Lanraragi下载页面选择对应的版本下载安装,windows的话直接下载.msi安装即可,如果是在linux上搭建的话,推荐使用dcoker,教程可以参考使用Docker安装LANraragi,打造你的漫画仓库,这个也是汉化过的,本人也是使用的这个镜像。
★软件的数据库和索引文件是独立出来的,运行时会经常读取这两个文件,推荐将这两个放在SSD中,可以有效提升使用体验。
2. 插件配置
大部分配置可以根据自己喜好选择,比如压缩图像质量,如果只是局域网使用便不用开启,如果想要在外网顺畅使用,则还是推荐开启。
插件方面,自带的几个插件也都比较实用,可以自己尝试一下,个人推荐开启下面两个插件的自动运行,开启自动运行的插件会自动将入库的文件进行刮削。
ChineseMeta
E-Hentai_CN
其中E-Hentai_CN插件是一位大佬魔改后的,可以直接获取汉化版本的 Tag,安装方式也可以直接参考项目文档,值得一提的是大佬还做了一个英文转换中文的脚本,如果是通过其他插件获取的英文 Tag ,又或者是之前已经刮削过英文 Tag 的,都可以用这个脚本进行一件转化。
E-Hentai_CN
项目地址:https://github.com/zhy201810576/ETagConverter
ETagConverter
项目地址:https://github.com/zhy201810576/ETagConverter/releases/tag/alpha-0.0.1
3. 文件库设置
由于Lanraragi是会检索档案库的所有符合要求的压缩包文件,并且是以路径来整合数据库的,所以并不会改动原有文件和路径。因此可以直接将上面 Calibre 整理好的本子库作为 Lanraragi 的档案库使用,两者的优缺点刚好互补。
Calibre
优点: 文件管理方便,操作直观简洁。
缺点:在线阅读体验差,需要将整个文件缓存至本地,并且不会记录阅读进度。
Lanraragi
优点: 在线阅读体验良好,可记录阅读进度。可以实时监测档案库的文件变动。
缺点: 文件管理约等于没有,刮削插件需要文件命名标准化
开始整理文件吧!
上面两者都设置好后,就可以将本子库导入了。
- 将文件拖入 Calibre ,检查自动识别的名字和作者有无错漏
- 右键批量获取元数据,检查元数据是否对应,按确定进行改写
- 整理完成!
{kind=link}
{kind=link}
 微信
支付宝
微信
支付宝